这是个啥问题
Pre-train广为采用
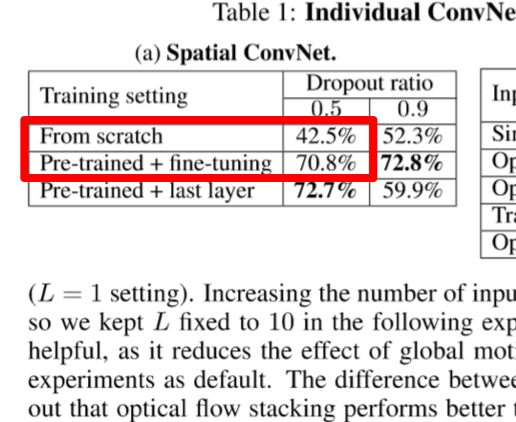
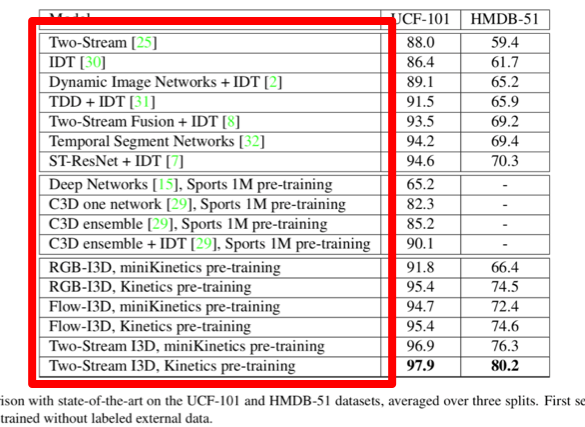
随着CNN在CV中的广泛应用,使得视觉问题的分类性能大幅提升,不是分类问题的也大多转化成分类问题套用CNN。在实验中普遍采用了网络预处理的步骤:针对研究的问题提出模型设计网络,对网络使用ImageNet(经典带标注的大规模图像数据集)做pre-train,然后在自己的问题中fine tune。这个操作普遍可以使训练相对于随机初值有一定的提升,比如two-stream action,它的spatial stream随机初值精度40%,而使用ImageNet pre-train之后能达到70%。如下图:
 |
 |
|---|---|
| Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576. | Carreira J, Zisserman A. Quo vadis, action recognition? a new model and the kinetics dataset[C]//Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017: 4724-4733. |
Why
为什么这么做有提升?普遍的解释是预训练得到的权值,包含了其所用数据集的信息。在此基础之上做fine tune,就利用了这些信息。在机器学习的范畴内,如果模型相近任务类似,自然是学习过程中用到的信息越多,结果越好。
更好的pre-train?
但这样的问题是,尽管ImageNet规模很大,常用来做pre-train效果也不错,但相对于unlabeled data体量还是太小了。为了利用更多的数据,很明显也就有两大出路:
- 扩大带标注的数据集。宗旨就是不断的标,依托大量的人力。在此基础之上产生了很多为了省人力的标注数据的工作,方法各异,但不管怎样都是为了得到更大规模的带标注的数据集。
这样做好处是pre-train和train都是分类问题,网络结构可以保持,对pre-train的权值有良好的利用,原理也更加合理。 - 利用无标注的数据。直接利用无标注的数据得到预训练权值,也是研究的另一种思路。当数据不再受标注的限制,就可以利用无限的数据来帮助模型的训练,提升效果。
但正因为没有标记,也就意味着pre-train并不能直接用分类的模型来设计,需要一定的转化。而且得到的预训练权值,从解释性角度来讲,用来做研究问题的分类训练也是需要转化的。正如此,已有工作利用unlabeled data的效果并不好,目前为止还是直接塞ImageNet做预训练最好。
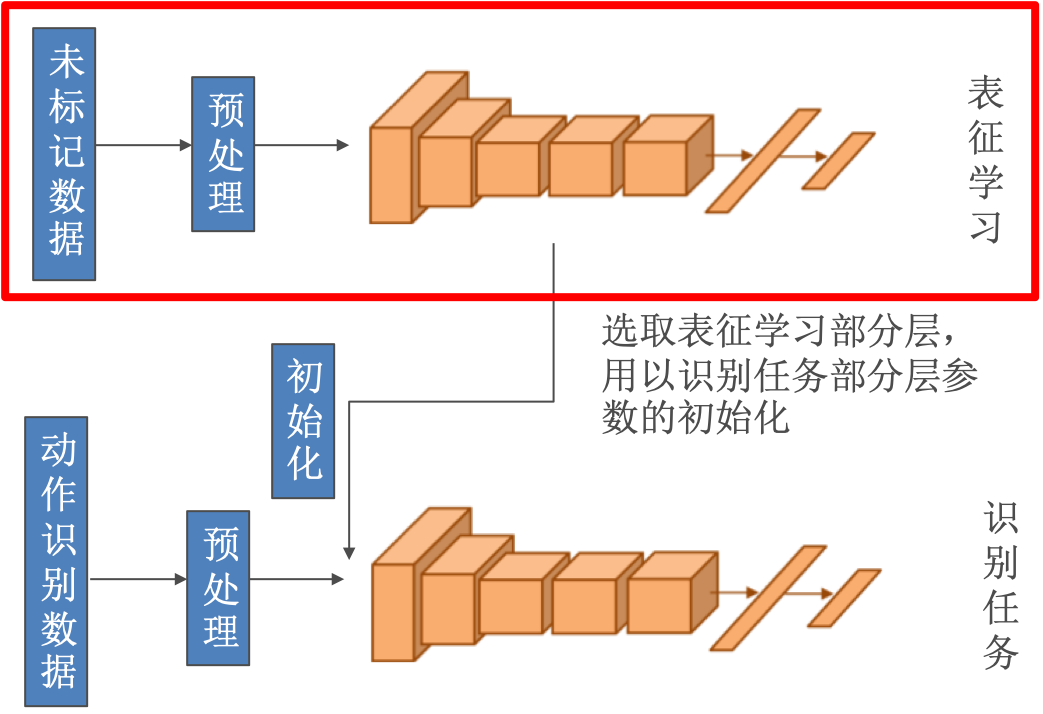
处于对CNN模型的理解,可以认为pre-train得到的权值(或其中一部分),是一种表征。
在视频动作识别问题中,对预训练有格外的依赖,表征学习也发展为一个分支。
具体来说流程如下:
近年工作
Patch Tracking
Wang X, Gupta A. Unsupervised learning of visual representations using videos[J]. arXiv preprint arXiv:1505.00687, 2015.
对视频中的目标进行跟踪,得到目标序列。采用triple Siamese Network,第一路是个目标序列的头,第二路是目标序列的尾,第三路是无关项。设计网络输出为比较三路目标的相似度,得到网络权值。
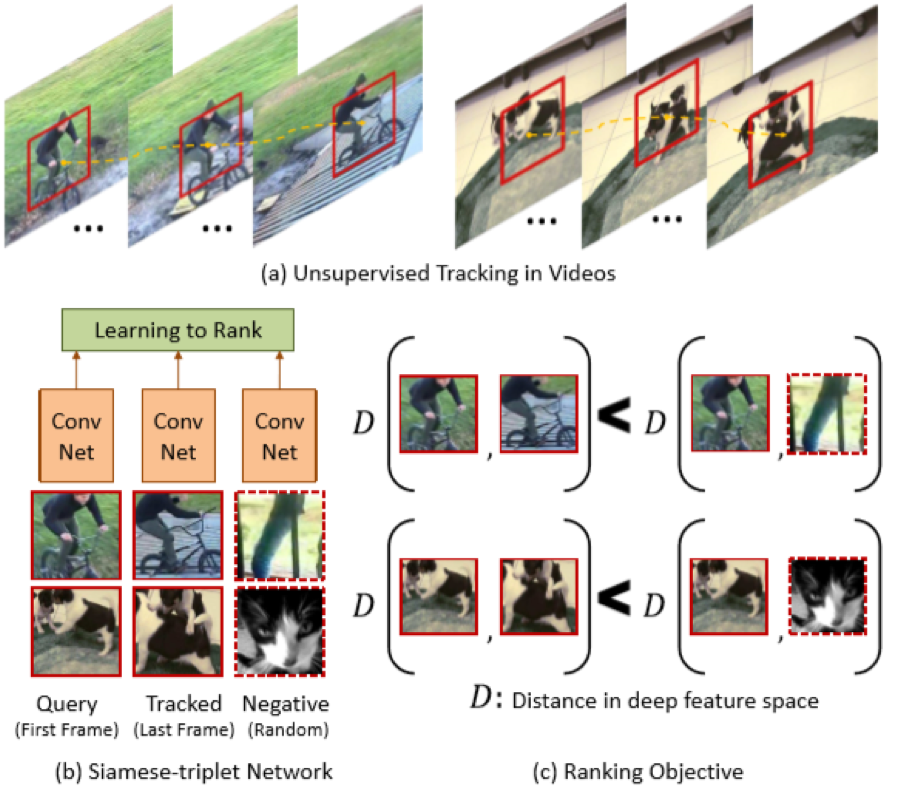
损失函数设计为
其中,
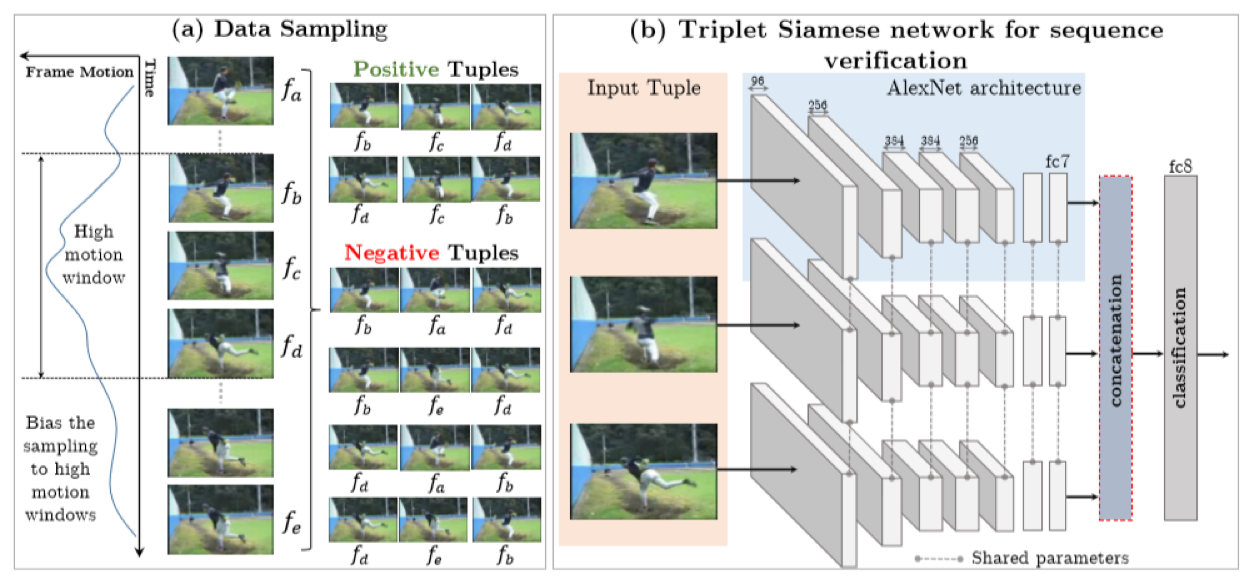
Tuples Order
Wang X, Gupta A. Unsupervised learning of visual representations using videos[J]. arXiv preprint arXiv:1505.00687, 2015.

还是triple Siamese Network,但是每一路的输入有变化。以视频序列中的三帧为输入,符合自然顺序的为正,不符合为负,转为分类问题。
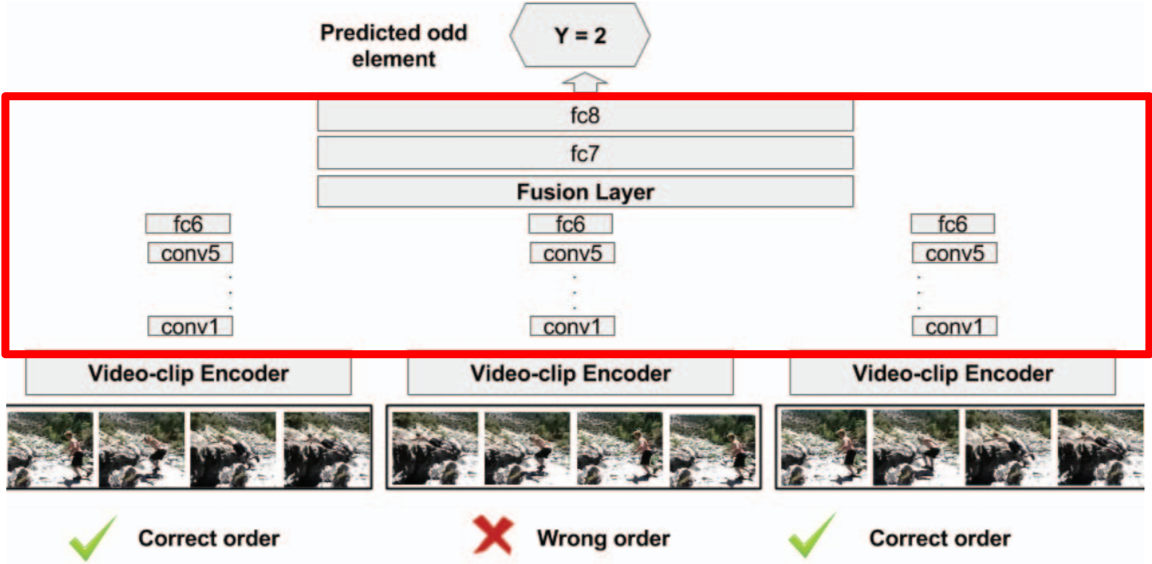
O3N
Fernando B, Bilen H, Gavves E, et al. Self-supervised video representation learning with odd-one-out networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017: 5729-5738.
扩展为更多路的Siamese Network,每一路输入为一个单独的样本,样本是视频序列中6帧的编码,编码方法比如为Dynamic Image。6帧的采样,以自然顺序为正,非自然为负,总体只有一路的错误的。转化为判断哪一路为错误的分类问题。
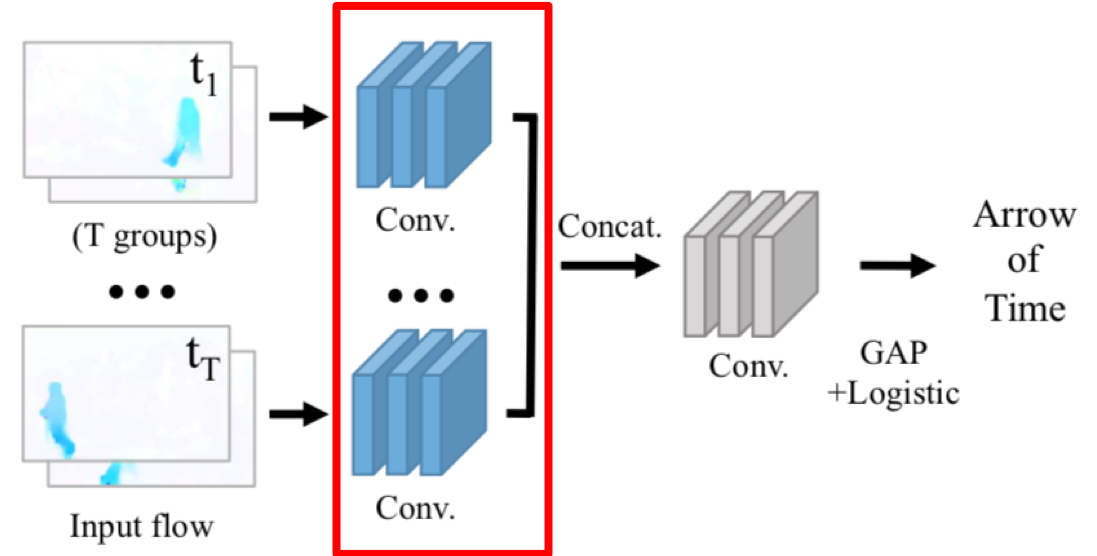
AoT
Wei D, Lim J, Zisserman A, et al. Learning and using the arrow of time[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8052-8060.
这个问题的解决,是采用了建立带标注新数据集的方法。但是不同于ImageNet,这个数据集是专门为了研究视频中动作区域建立的,虽然需要人力,但是规模比ImageNet小的很多,但却达到了相同的pre-train效果。